How Large Language Models Work
A primer on LLMs: from tokens, embeddings, and Transformers to training, RAG, tool calling, multimodality, and end-to-end product flows.

A large language model is not a human mind simulated in software. It is a large probabilistic model trained to predict the next token from the context it receives. Text is split into tokens, tokens are mapped into vectors, those vectors are processed through many Transformer layers, and the model then decodes an output one token at a time [1][2][11].
Production LLM systems add infrastructure around that core loop: context management, retrieval, tool calls, multimodal input processing, safety controls, and evaluation systems [14][18][23][24][29][30][34].
Part I · How a language model works
Chapter 1 · What an LLM really is
Concept. An LLM can be described as a high-capacity autocomplete system. Given a context, it repeatedly estimates the most likely next token. Because it has been trained on a very large volume of text, the same next-token objective supports conversation, writing, translation, coding, summarization, and behavior that can resemble reasoning. The precise formulation is this: an autoregressive language model estimates the conditional distribution of the next token given the preceding context.
Mechanism. GPT-style models learn an approximation of P(next token | preceding tokens). The GPT-3 paper showed that, when model size, training data, and compute scale sufficiently, this objective can produce broad capabilities across question answering, translation, completion, code, and few-shot tasks [2]. The Transformer architecture makes this modeling tractable at scale [1]. A model’s parameters compress a large amount of linguistic, factual, and procedural structure; that compression should not be confused with human awareness, subjective experience, or human-style understanding.
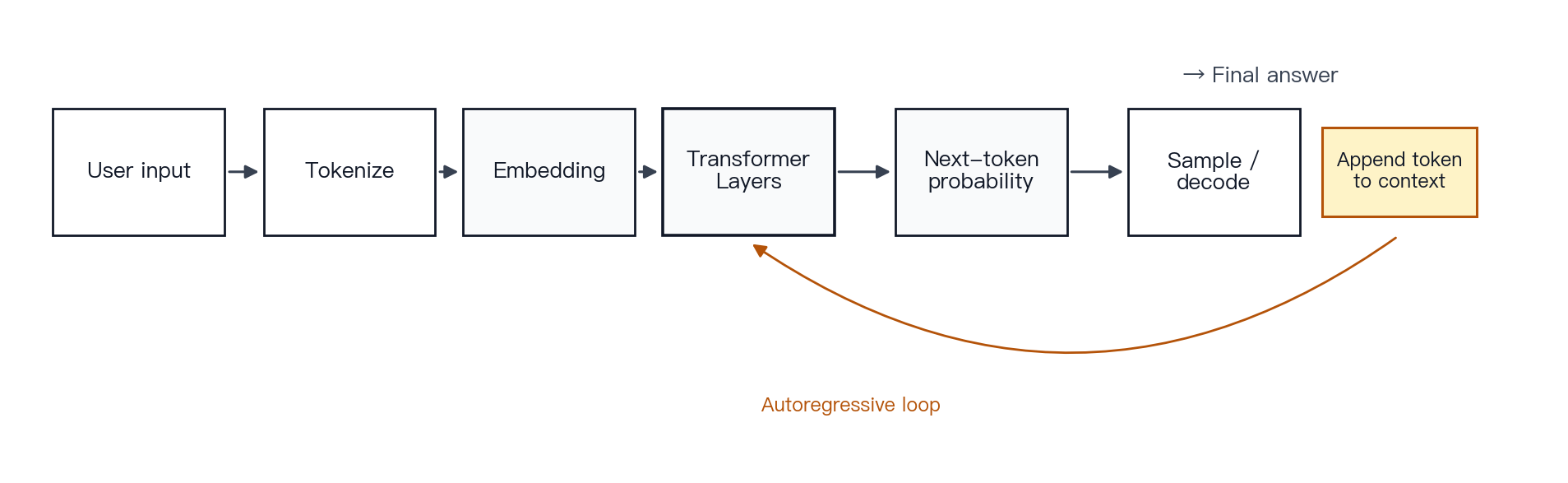
Figure 1 · High-level LLM flow. User input moves through tokenization, vector representation, Transformer layers, and token-by-token generation. The flow combines autoregressive language modeling with the Transformer architecture.
Example. A user asks, “Explain what a black hole is.” The model does not first write a complete encyclopedia entry. It generates one token after another, producing “A,” “black hole,” “is,” “a,” “region,” and so on, extending the answer until the response is complete.
Common misconception. An LLM is a search engine. Search engines retrieve existing documents; databases store and return exact records; classical programs execute deterministic rules; LLMs generate probable text from context. An LLM can be connected to search, databases, and tools, but it is not the same as those systems.
Key point. An LLM is not primarily a chatbot. At its core, it is a large probability model that predicts the next token from context.
Chapter 2 · What tokens are
Concept. Models do not process language the way humans do. They process text as a sequence of tokens. A token can be a character, a word, a subword fragment, a punctuation mark, or a leading space plus part of a word.
Mechanism. Tokenization converts raw text into a sequence of model-readable tokens. Modern models usually use a subword method such as Byte-Pair Encoding (BPE), which keeps the vocabulary manageable while still handling rare words, new words, and many languages [7]. OpenAI’s developer documentation makes the point concrete: a token can be as short as one character or as long as one word, and whitespace and punctuation also count [35]. Different languages, models, and tokenizer implementations can split the same string in different ways.
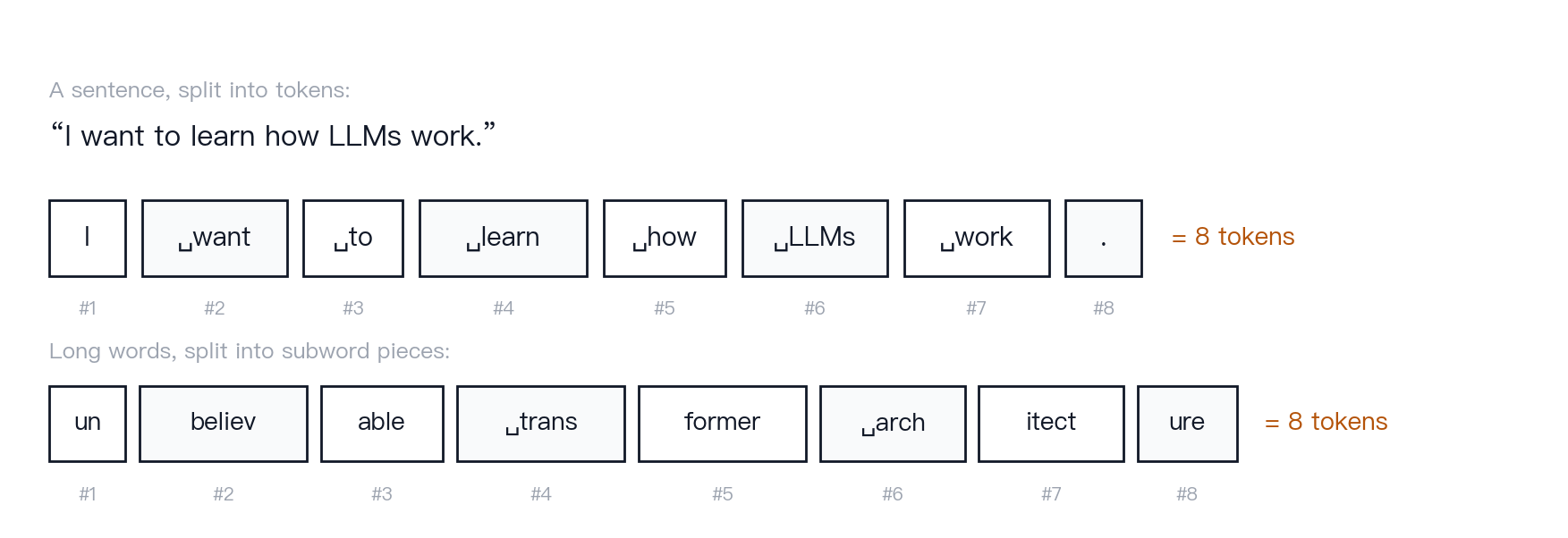
Figure 2 · Token splitting. An illustrative English and mixed-language split, designed to explain the concept rather than reproduce one specific tokenizer. Token count matters because it affects cost, latency, and how much information fits into the context window.
Common misconception. One token equals one character or one word. A token is the unit produced by the model’s tokenizer. Tokens often do not align cleanly with human categories such as “character” or “word.”
Key point. The model processes tokens, not characters. In engineering terms, the token is the budget unit.
Chapter 3 · Embeddings: turning text into computable numbers
Concept. Computers do not directly process words such as “cat,” “dog,” or “black hole” as meanings. They process numbers. The model maps each token to a vector, a dense numerical representation. Tokens with similar usage patterns tend to occupy nearby regions in vector space.
Mechanism. Early work on word vectors showed that distributed representations can capture semantic and syntactic regularities [6]. Transformer-based models go further. They do not stop at static token embeddings: each layer rewrites the representation in context, so the same word can have different internal representations in different sentences. Analyses of BERT and related models show that this contextualization becomes stronger in higher layers [8][9]. For example, “apple” in “I ate an apple” and in “Apple launched a phone” receives different contextual representations.
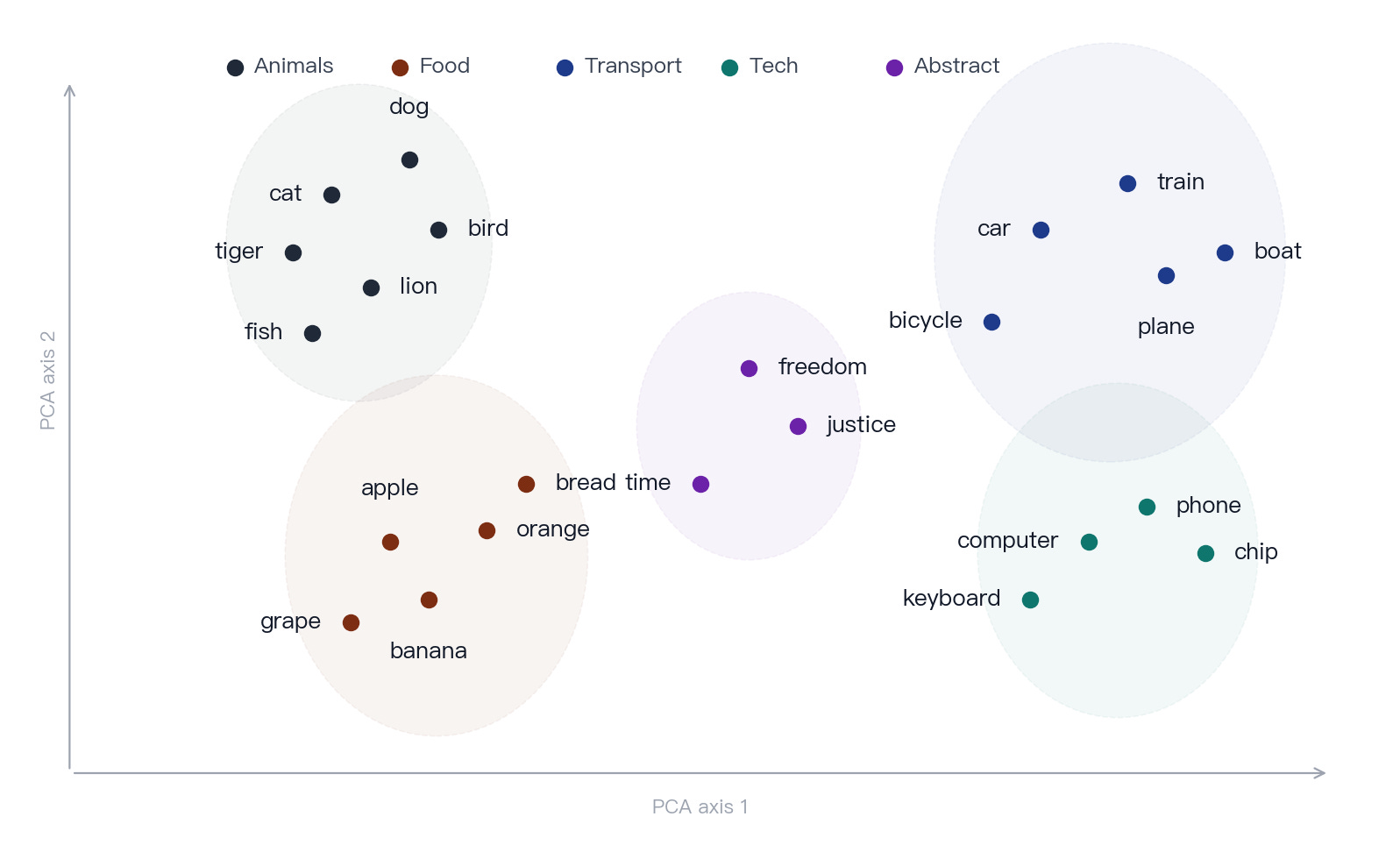
Figure 3 · Embedding projection. An illustrative two-dimensional projection of an embedding space. Real embeddings live in hundreds or thousands of dimensions, but semantically related words still tend to occupy nearby regions.
Example. If a model repeatedly sees sentences such as “cats meow,” “cats run,” and “cats are animals,” along with “dogs bark,” “dogs run,” and “dogs are animals,” it learns internal representations that place “cat” and “dog” closer together than “cat” and “refrigerator” or “cat” and “locomotive.”
Common misconception. An embedding is just a numeric ID for a token. The ID is a discrete lookup key; the embedding is the dense learned vector used in computation. In modern Transformers, that vector is updated layer by layer as context is incorporated.
Key point. Embeddings convert language from symbolic text into numerical representations the model can compute over.
Chapter 4 · Transformer and self-attention
Concept. If tokens are the input units and embeddings are their numerical representations, the Transformer is the architecture that updates those representations. It repeatedly processes the sequence and determines which other positions are relevant for each position.
Mechanism. The defining mechanism of the Transformer is self-attention. Unlike a classical RNN, which passes information forward one step at a time, self-attention allows a token position to route information directly from other allowed positions in the sequence. In decoder-only autoregressive models, causal masking prevents a position from attending to future tokens during generation. The original Transformer paper introduced multi-head attention: multiple attention heads run in parallel and capture different relationships from different representation subspaces [1]. Later analyses of BERT showed that some heads are strongly associated with syntax or coreference relations [10].
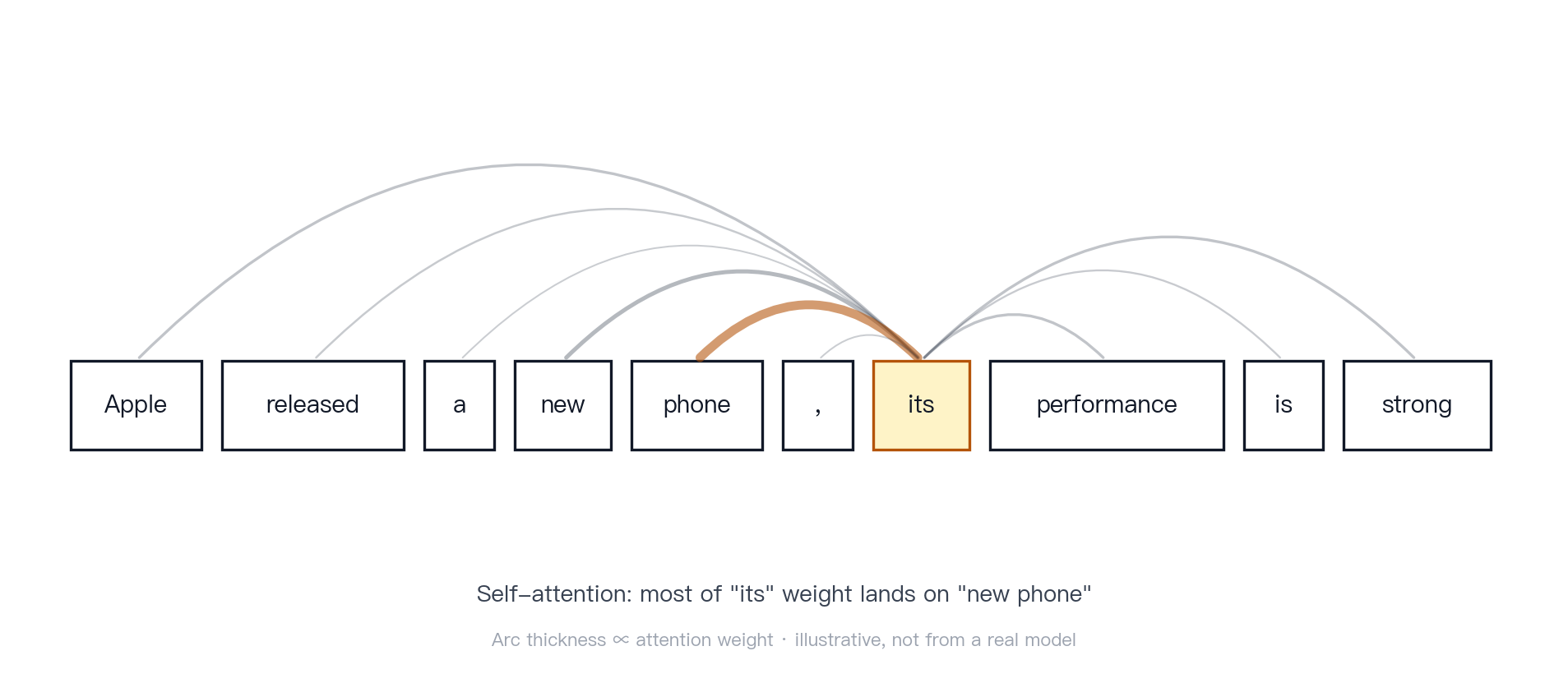
Figure 4 · Self-attention example. In “Apple released a new phone; its performance is strong,” attention can route weight from “its” toward “new phone” rather than “Apple.” This does not mean the model has human-like understanding of coreference; the learned weighting mechanism assigns weight where the context supports it.
Common misconception. Attention is exactly “what the model is looking at.” Attention is a learned weighting mechanism. It often aligns with human intuition, but it is not a complete explanation of the model’s behavior or cognition.
Key point. The Transformer makes long-range dependencies tractable by allowing direct information routing across positions, subject to the model’s attention mask.
Chapter 5 · How representations are refined layer by layer
Concept. A Transformer is built from multiple layers. A useful way to picture them is a series of editors working on the same draft: an early pass attends to wording and local patterns, later passes to sentence structure, and the final passes to meaning and intent. Each layer rewrites the representation it receives and passes an updated version to the next. The output is not produced by one layer alone; it emerges from repeated representation updates.
Mechanism. Probing studies of Transformer-style models such as BERT show recurring patterns: lower layers tend to encode surface features, middle layers tend to track syntax, and upper layers tend to encode more semantic and task-relevant information [9]. Higher layers are also more strongly contextualized and depend more on the full sequence [9][10]. This does not mean the model thinks in a fixed sequence of human-like stages; a more precise description is that hidden states are repeatedly rewritten as they pass through the stack.
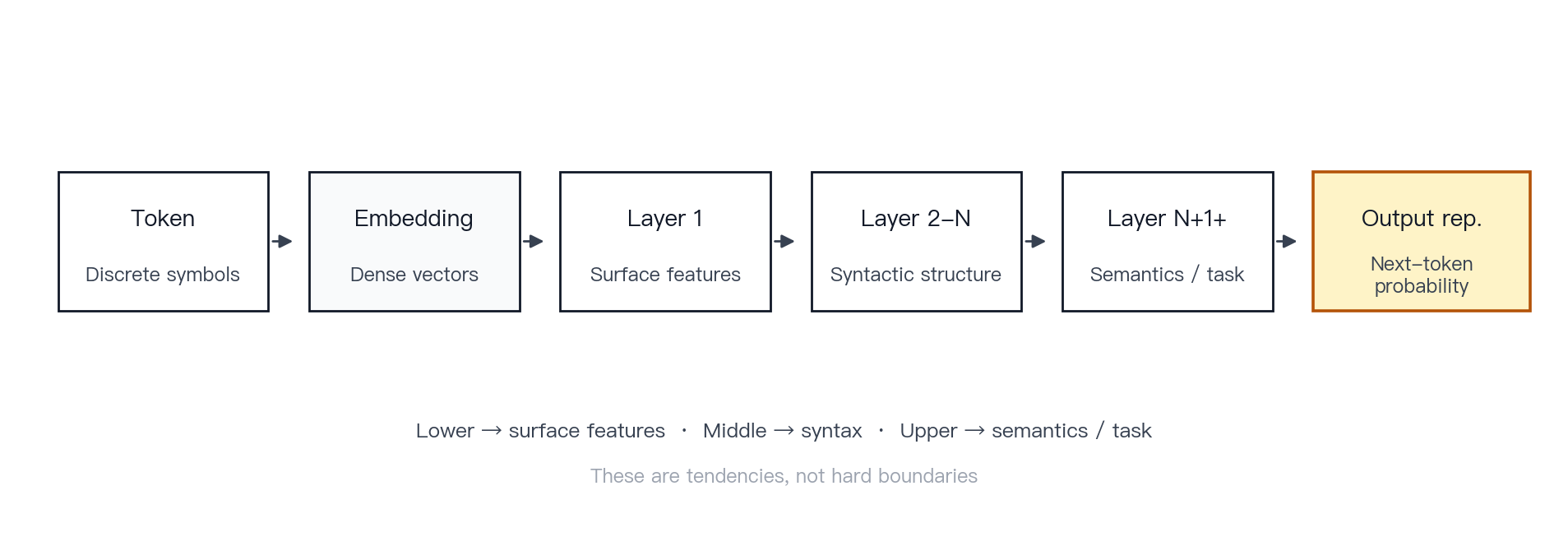
Figure 5 · Multi-layer Transformer. Token to embedding to layers to output representation. No single layer produces the answer; each layer reorganizes the representation for the next layer.
Example. The word “bank” means different things in “I went to the bank to deposit cash” and “the bank of the river.” As a sentence moves through the layers, these two uses become more clearly separated in the model’s internal representation.
Common misconception. Layer 1 handles grammar, layer 2 handles meaning, and layer 3 handles logic. These are tendencies, not strict assignments. Layers, tasks, and model families overlap in what they encode.
Key point. A mechanical translation of “the model is thinking” is: the hidden representation is being rewritten across layers.
Chapter 6 · Why the model can generate answers
Concept. The model does not draft a complete answer before producing text. It generates incrementally: choose the next token, append it to the context, recompute the next distribution, and repeat.
Mechanism. At inference time, an autoregressive language model decodes one token at a time. At each step it produces a probability distribution over the vocabulary, a decoding strategy selects a token from that distribution, and the selected token becomes part of the context for the next step. Holtzman et al. make an important distinction: the distribution produced by the model and the sampling strategy used to choose from it are separate components [11].
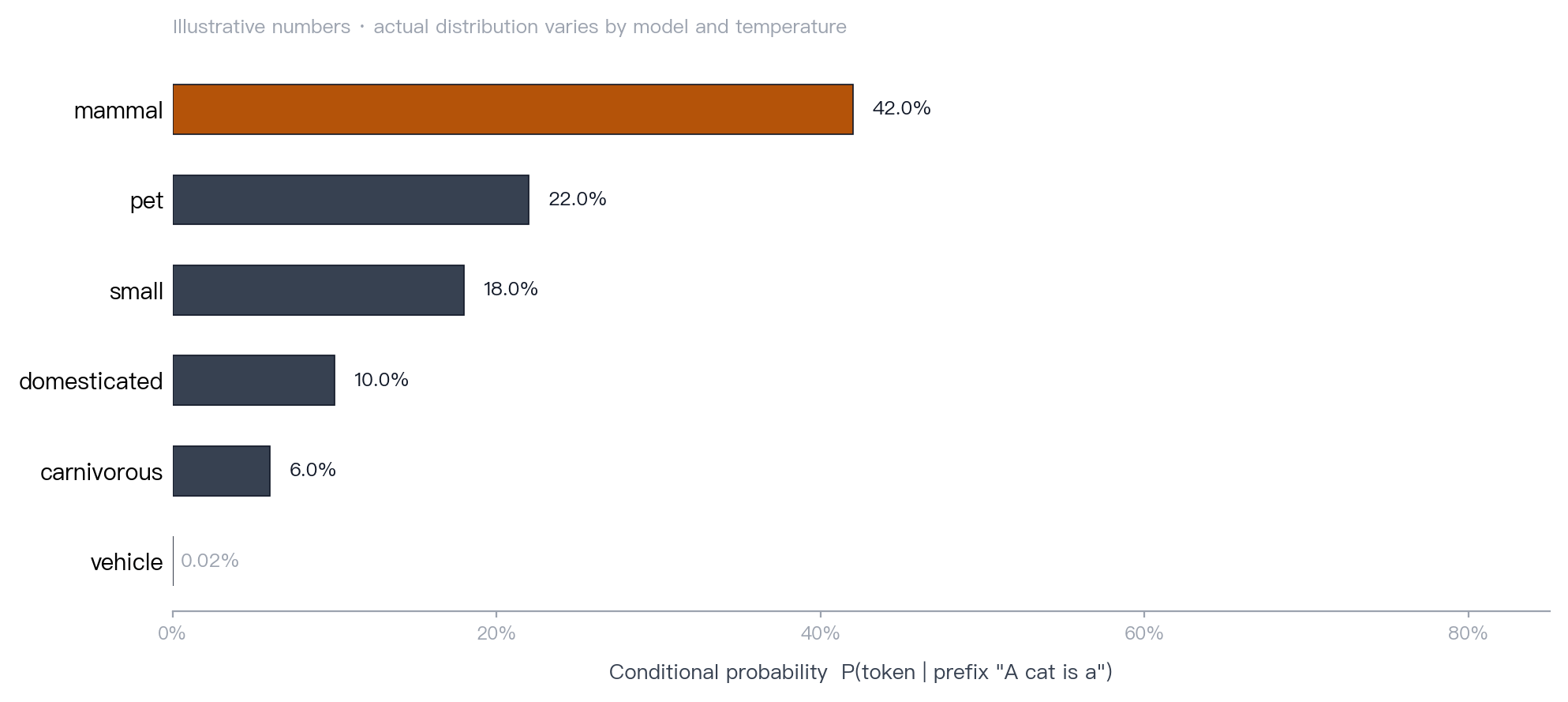
Figure 6 · Next-token distribution. After the prefix “A cat is a,” the model assigns probability mass across the vocabulary. The displayed numbers are illustrative.
Common misconception. The model secretly writes the whole answer first and streams it slowly. Most production generative LLMs generate one token at a time during inference.
Key point. Generation is not a paragraph produced in one step. It is a probability distribution plus a decoding loop.
Chapter 7 · Temperature, top-k, and top-p
Concept. The same model can produce conservative or varied outputs depending on its sampling parameters. The underlying model may be unchanged; the selection process changes.
Mechanism. Temperature adjusts the shape of the probability distribution. Low temperature sharpens the distribution and increases the dominance of high-probability tokens; high temperature flattens the distribution and gives lower-probability tokens more room to be selected. Top-k sampling keeps only the k most likely candidates before sampling. Top-p sampling, also called nucleus sampling, keeps the smallest set of candidates whose cumulative probability mass reaches p. Holtzman et al. introduced nucleus sampling to reduce the repetitive and degenerate text often produced by purely greedy maximum-likelihood decoding [11].
Common misconception. Higher temperature makes the model smarter. Higher temperature makes token selection more random. Creativity may increase, but so may the error rate.
Key point. Sampling parameters do not change the model. They change how the model selects an output from its own distribution.
Part II · How the model is trained and scaled
Chapter 8 · How LLMs are trained
Concept. Training moves a model from broad language modeling toward useful assistant behavior. First, the model learns statistical patterns from large text corpora. Then it is trained on curated demonstrations to follow instructions. Then its behavior is shaped toward human preferences and safety requirements. Finally, it is evaluated and stress-tested.
Mechanism. A standard pipeline has four stages. Pretraining runs next-token prediction over large corpora to learn language patterns and broad world knowledge. Supervised fine-tuning (SFT) continues training on curated instruction-response demonstrations. Preference alignment (methods such as RLHF and DPO) shapes behavior toward outputs humans prefer, including helpfulness, honesty, and harmlessness. Safety training and evaluation use policies, red-teaming, refusal strategies, and evaluation pipelines to reduce risky outputs. InstructGPT formalized the SFT-plus-RLHF recipe [12]; DPO proposed a simpler, more direct method for preference optimization [13]; Constitutional AI showed that a written set of principles plus AI feedback can also guide alignment [14].
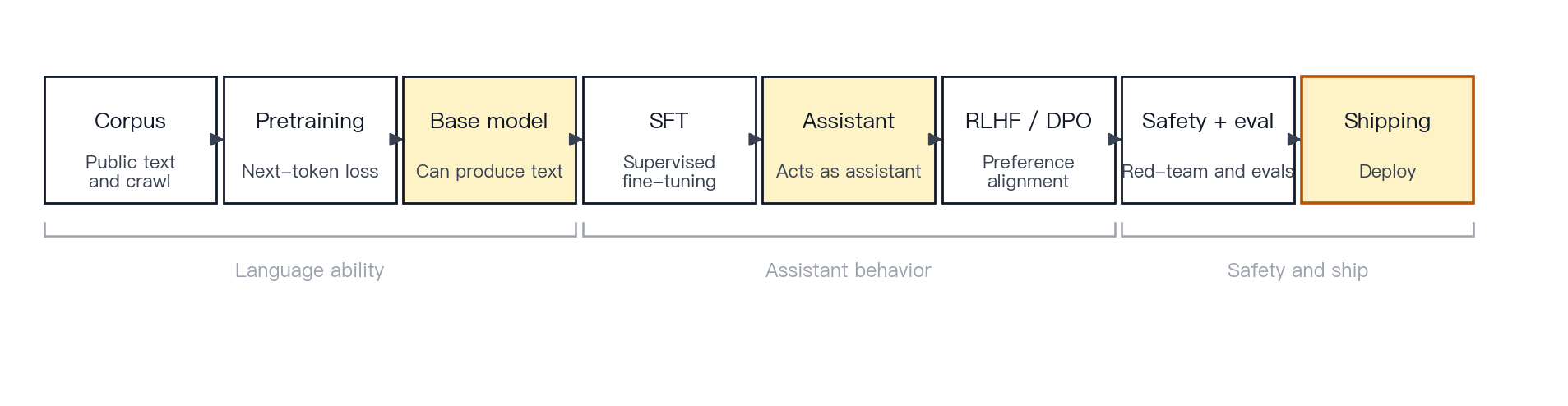
Figure 7 · Training pipeline. Data to pretraining to SFT to alignment to safety to deployment. Pretraining teaches broad language behavior, SFT teaches instruction following, preference alignment shapes user-preferred behavior, and safety training defines boundaries.
Example. Pretraining teaches the model to produce coherent language. SFT teaches it to behave like an assistant. Preference alignment teaches it which responses users are likely to prefer. Safety training teaches it when to refuse, hedge, or redirect.
Common misconception. Training copies an encyclopedia into the model. The model mostly compresses statistical patterns into parameters rather than storing a verbatim archive. However, research shows that models can memorize and reproduce fragments of training data [17]. The accurate view sits between “perfect copy” and “no memory.”
Key point. Training is not one event. It is a pipeline that moves a model from fluent language generation to assistant behavior within safety constraints.
Chapter 9 · Parameters and why 7B, 70B, and 175B matter
Concept. Parameters are the learnable numerical weights inside the model. In effect, they are a vast set of adjustable settings. Training adjusts these weights so that the model’s output distribution becomes better aligned with the training objective.
Mechanism. GPT-3 disclosed a 175-billion-parameter model [2]. LLaMA released a family ranging from 7B to 65B parameters [3]. Chinchilla used 70B parameters and, by training on more tokens, outperformed several larger models [5]. Scaling-law work and Chinchilla support a more precise conclusion: larger models often have higher performance ceilings, but actual performance depends on training tokens, data quality, architecture, and training discipline [4][5].
Figure 8 · Parameter-knob analogy. A model can be understood as a large system of learnable weights. Training updates those weights so the output distribution moves closer to the target.
Example. The “B” in 7B, 70B, and 175B means billion. A 7B model has roughly 7 billion parameters; a 70B model has roughly 70 billion. More parameters generally increase capacity, but they also increase memory requirements, reduce inference throughput, and raise deployment cost.
Common misconception. More parameters always mean a better model. Parameter count is one part of capacity. A well-trained 70B model can outperform a much larger model trained poorly.
Key point. Scale matters, but scale alone does not determine model quality.
Chapter 10 · Context windows
Concept. The context window is the model’s working input space, a finite workbench on which everything the model can currently see must fit: instructions, conversation history, user input, retrieved documents, tool outputs, and the model’s own output budget. A larger context window allows more information to be visible at once, but more context does not automatically mean better use of context.
Mechanism. The context window is the maximum number of tokens the model can process in a single request. Anthropic’s documentation describes the window as containing the conversation history, the current request, and the space needed for the model’s output [38]. In real agent and coding workflows, the same window may also include a system prompt, file contents, previous model responses, and tool results. Long contexts carry real system costs: higher prefill compute, KV-cache memory pressure, and higher latency. Serving work such as vLLM and PagedAttention focuses on making this cheaper at scale [33]. The “Lost in the Middle” result shows that more context is not always better: important evidence placed in the middle of a long prompt can be underused [22].
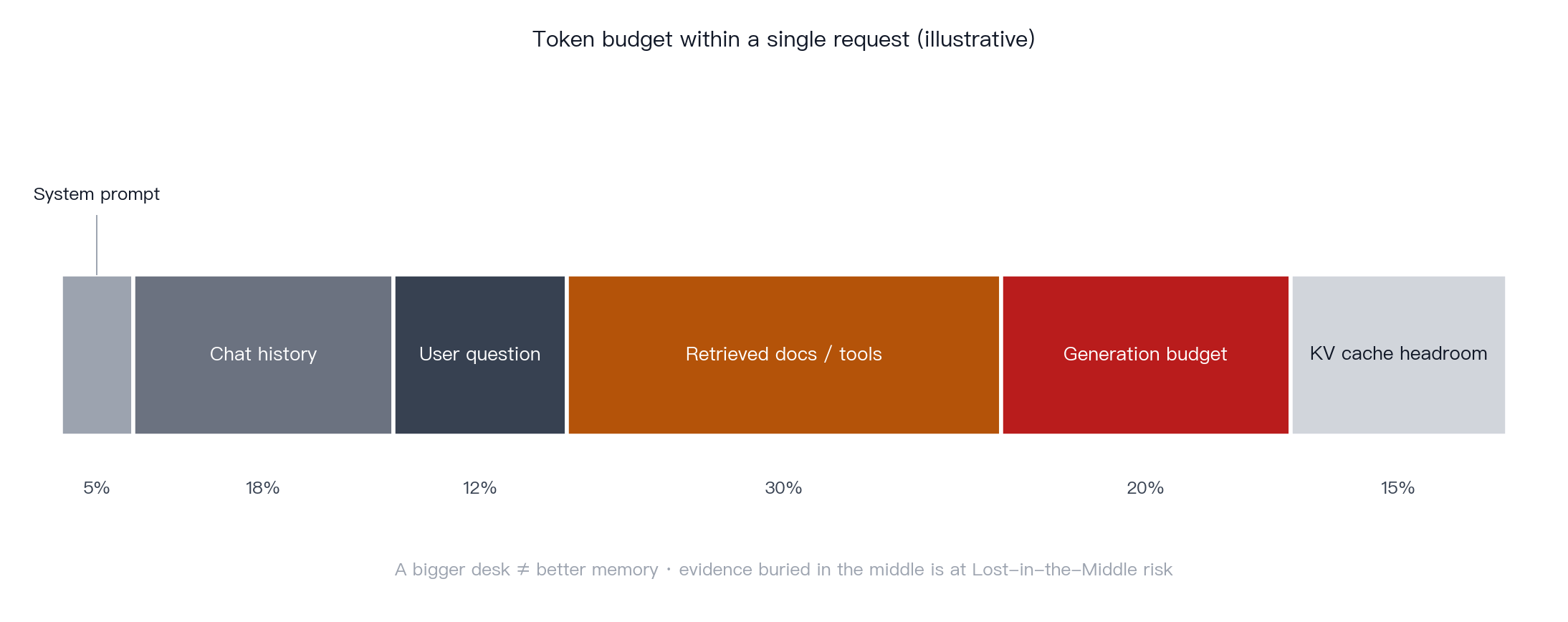
Figure 9 · Context window composition. System prompt, conversation history, user request, retrieved passages, and tool returns share one finite token budget with the model’s generation budget.
Engineering note. Production systems usually combine long contexts with truncation, summarization, retrieval, and caching. OpenAI and Anthropic both provide prompt-caching features to reduce latency and cost when long, stable prefixes are reused in long-document workflows [37][40].
Common misconception. A large enough context window means the model remembers the user forever. The context window contains what is visible in the current request or session. It is working memory, not permanent memory.
Key point. The context window is one of the most important constraints in the LLM stack. It controls what the model can see, how much the request costs, and how much latency the system incurs.
Part III · Retrieval, tools, and multimodality in real products
Chapter 11 · Why hallucinations happen
Concept. A hallucination is not intentional deception. It is a reliability failure in which the model produces fluent text that is factually wrong.
Mechanism. A working definition of hallucination is an output that is linguistically plausible but factually incorrect. Surveys identify several causes: limited or stale parametric knowledge, biased or incomplete training data, ambiguous prompts, absent retrieval, and a decoding process that tends to produce answer-shaped text rather than acknowledge uncertainty [15]. OpenAI’s research write-up adds a sharper point: traditional training and evaluation can reward plausible guesses more than honest uncertainty [16].
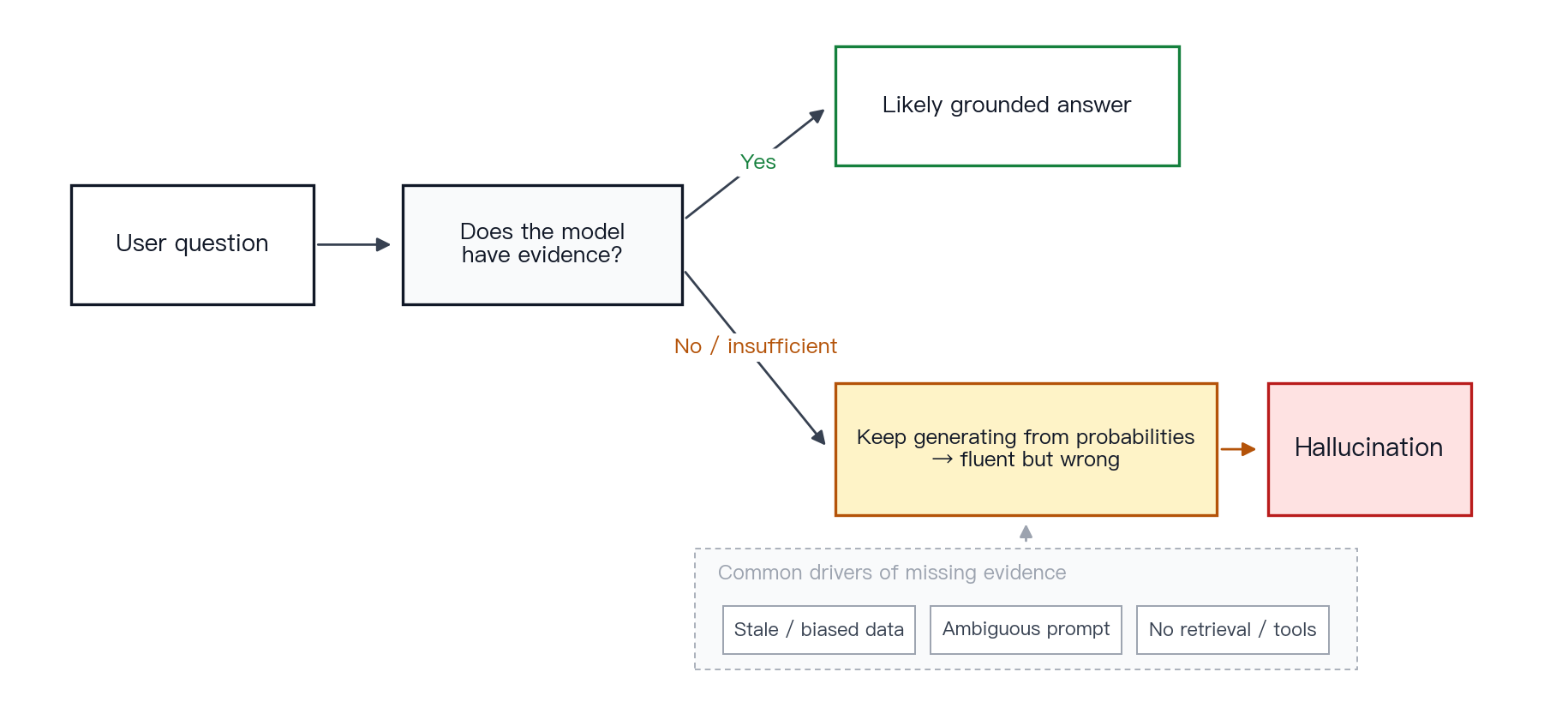
Figure 10 · Causes of hallucination. Stale or missing knowledge, vague prompts, and absent retrieval converge into probability-driven generation, producing fluent text that may not be true.
Example. Ask the model to summarize a nonexistent paper, such as “Smith et al. 2024 on Quantum Bubble Tea Optimization.” A model may invent authors, methods, and findings, because the generation process favors text that resembles a real abstract.
Mitigation. Reliable mitigations are engineering controls: require citations, add retrieval or search, ask the model to flag uncertainty, separate known facts from recommendations, and add human review for high-stakes domains such as medicine, law, and finance. Hallucinations can be reduced significantly; no single technique eliminates them completely.
Key point. Hallucination is a natural reliability cost of probabilistic generation on fact-sensitive tasks.
Chapter 12 · RAG and why it reduces hallucination
Concept. A plain LLM answers from two sources only: what is encoded in its parameters and what is provided in the prompt. In effect, this is a closed-book exam. Retrieval-augmented generation (RAG) adds a third source: external evidence retrieved before generation, the equivalent of letting the model consult reference material first.
Mechanism. RAG stands for retrieval-augmented generation. Lewis et al. describe it as combining parametric memory with non-parametric external memory: retrieve relevant documents, place them into the context, and generate an answer using that material [18]. The retriever can be dense; DPR showed that dense retrieval can outperform strong BM25 baselines on open-domain question answering [19]. Vector databases and approximate nearest-neighbor indices support embedding search at scale; Faiss is a canonical implementation [20].
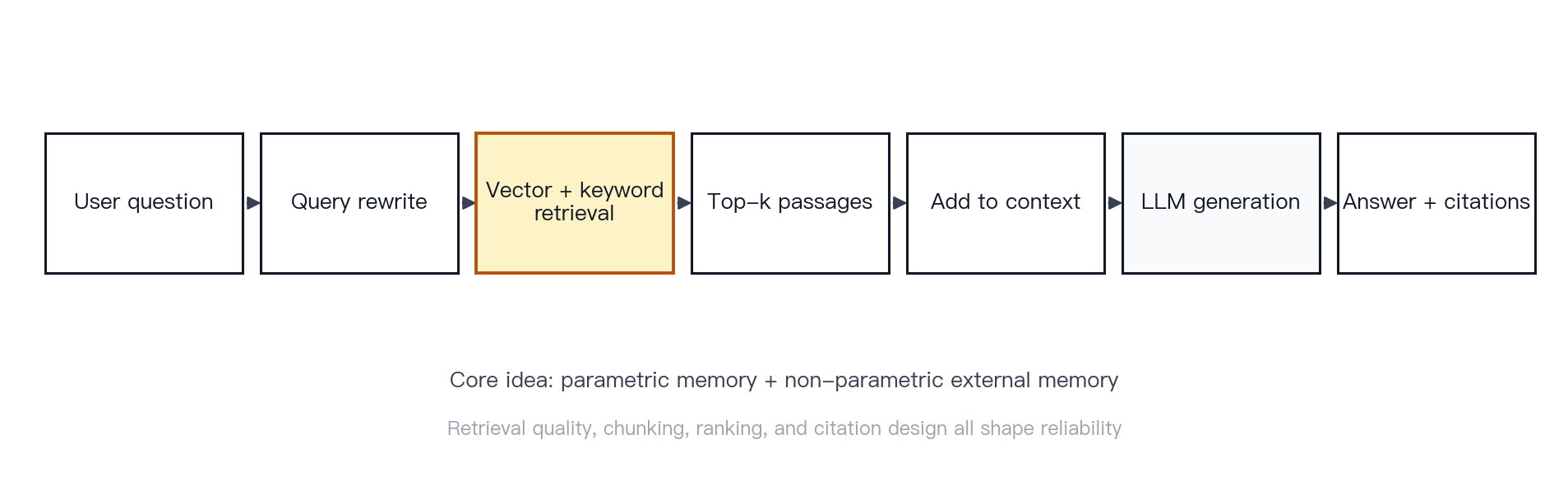
Figure 11 · RAG flow. Query rewrite, retrieve, context assembly, generation, and citation. Before generation, the system retrieves dense and/or keyword-matched passages and injects the top passages into the context.
Limitations. If retrieval fails, or if too much irrelevant material is inserted into the context, the answer can still be wrong. CRAG explicitly addresses what to do when retrieval quality is poor [21]. The “Lost in the Middle” result shows that even when the right passage is present, the model may underuse it if it appears in the middle of a long prompt [22].
Common misconception. Adding RAG eliminates hallucinations. RAG changes the system from “closed-book” to “allowed to consult materials.” It does not automatically create a fact engine. Retrieval quality, chunking, ranking, prompt placement, and citation design all matter.
Key point. RAG replaces reliance on what the model may remember with information the model can see in the current context.
Chapter 13 · Tool use and agents
Concept. LLMs are strong at generating text. They are not inherently reliable at exact arithmetic, real-time lookup, or executing external actions. Tool use connects the model to systems that can perform those tasks.
Mechanism. The OpenAI tool-use loop is direct: the application describes the available tools, the model emits a structured tool call, the application executes the tool, the result is returned to the model, and the model incorporates the result into the final response [36]. Anthropic’s documentation describes the same general pattern: the model selects whether to call a tool, which tool to call, and what arguments to pass [39]. Toolformer showed that language models can learn when to call an API, what arguments to pass, and how to use the result [23]. ReAct interleaves reasoning steps and action steps so the model can alternate between planning and acting [24].
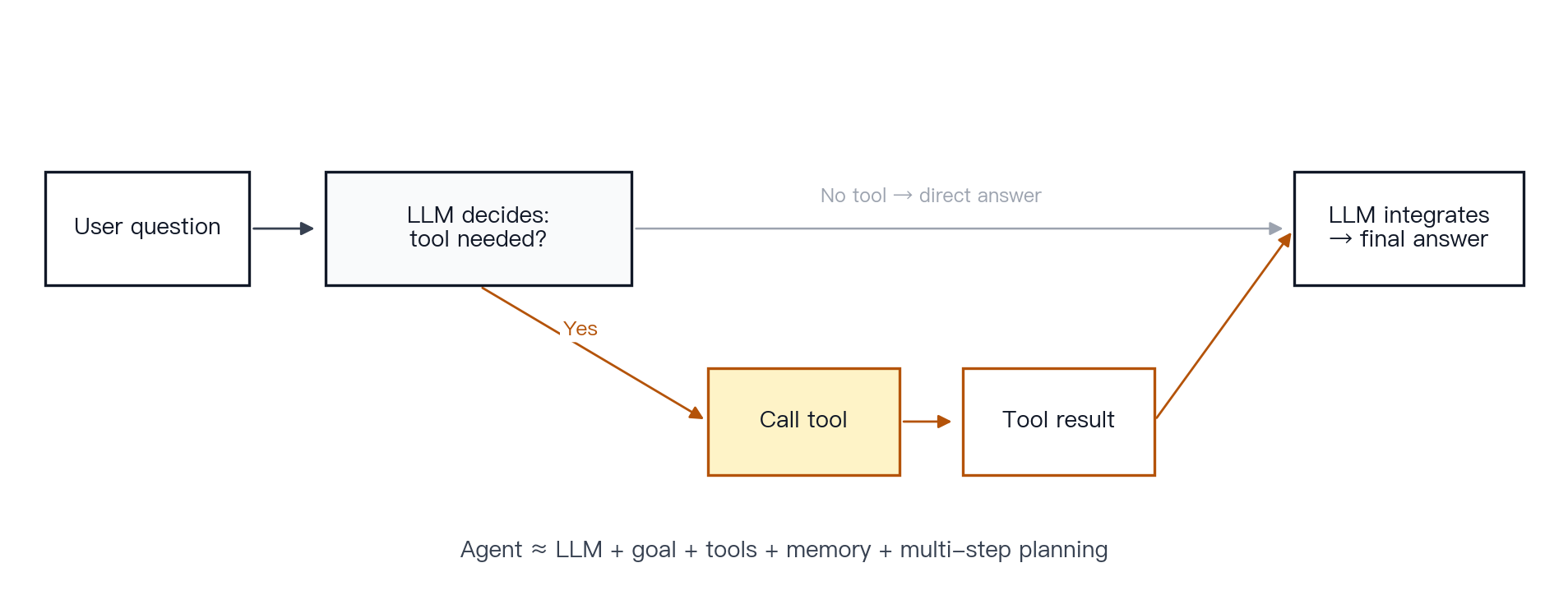
Figure 12 · Tool-use loop. Decide, call, return, integrate. The model does not execute the external action itself; it returns a structured call, the application runs it, and the result is fed back.
How to think about agents. A practical definition is agent ≈ LLM + goal + tools + memory + multi-step planning. Instead of answering one question at a time, an agent decomposes a goal, chooses tools, inspects intermediate results, and decides the next step. This pattern is powerful but brittle: a misread goal, a flawed plan, a wrong tool argument, or a misinterpreted result can derail the entire chain.
Example. A user asks, “What is today’s USD to EUR rate, and how much is 500 USD in EUR?” A plain LLM may guess. A system with a foreign-exchange lookup tool and a calculator can retrieve the current rate, perform the conversion, and explain the result.
Common misconception. Agents are already reliable digital employees. An agent is an application design pattern, not an autonomous personality. It can extend capability, but it can also amplify a single error across many steps.
Key point. Tools give the model external capabilities. Agents give the model a multi-step execution framework.
Chapter 14 · How multimodal models process images, audio, and video
Concept. Multimodal models do not perceive images, audio, or video the way humans do. They convert those inputs into representations that can be processed alongside text.
Mechanism. Vision Transformer (ViT) showed that an image can be divided into patches and processed by a Transformer as a sequence [29]. CLIP showed that images and text can be projected into a shared semantic space [30]. Flamingo and LLaVA advanced this line of work by connecting vision encoders to language models, enabling interleaved image-and-text input, visual question answering, screenshot understanding, and multimodal dialogue [31][32]. Video is typically represented as frames plus temporal structure.
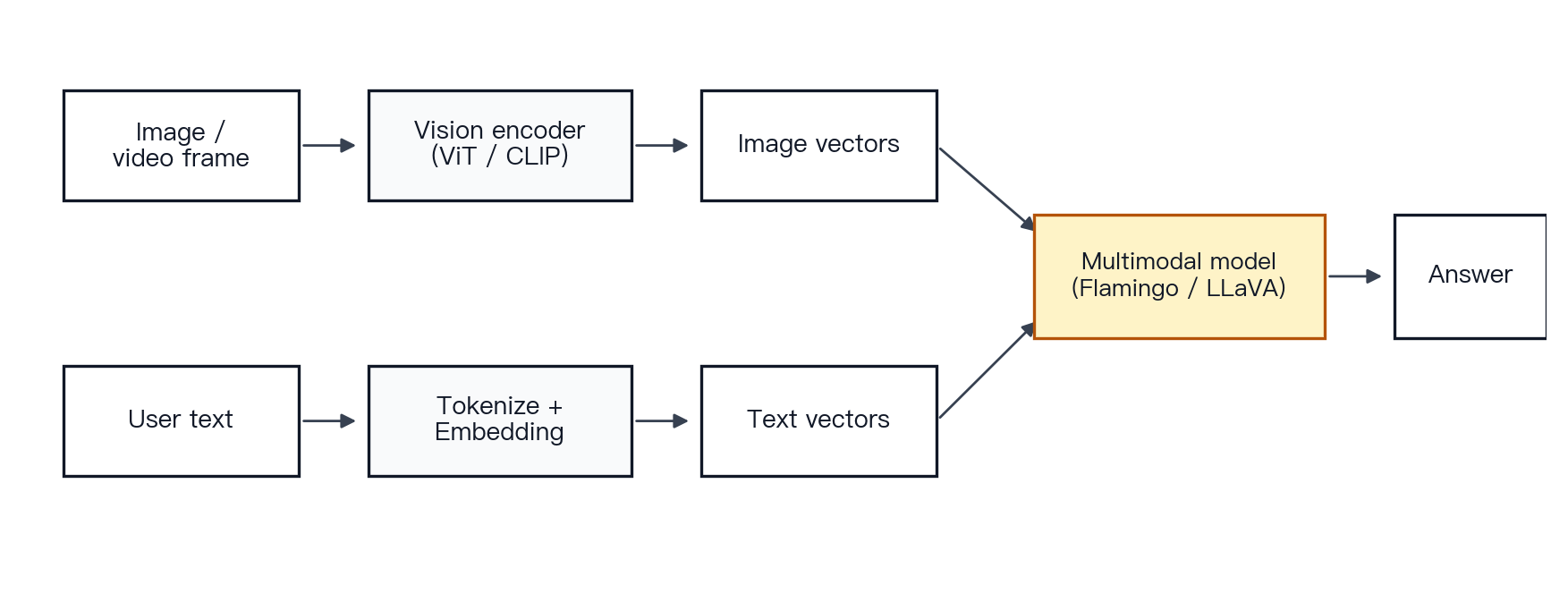
Figure 13 · Multimodal flow. Visual inputs are encoded, text inputs are tokenized and embedded, and both streams converge into a model that produces an answer.
Example. A user provides a screenshot of an earnings dashboard and asks, “What appears to be the main driver of margin compression?” The model encodes the image into visual features, combines those features with the text question, and generates an explanation.
Common misconception. A multimodal model literally sees the way a person sees. The model processes numerical representations produced by encoders. It does not have subjective visual experience.
Key point. Multimodality is the integration of multiple input types into a shared computable representation space.
Chapter 15 · Why models appear to reason
Concept. Much of what looks like reasoning comes from exposure to large numbers of worked examples during training, each pairing a problem with its solution steps and final answer. The model learns both the patterns and the language formats associated with them.
Mechanism. Chain-of-Thought prompting shows that explicit intermediate steps can improve performance on difficult reasoning tasks [25]. Self-Consistency improves accuracy by sampling multiple reasoning paths and voting on the answer [26]. Program-of-Thoughts delegates arithmetic to an interpreter [27]. Tree-of-Thoughts allows a model to explore a search tree and backtrack [28]. The shared principle is clear: explicit steps, external verification, and search over alternatives improve performance on multi-step problems.
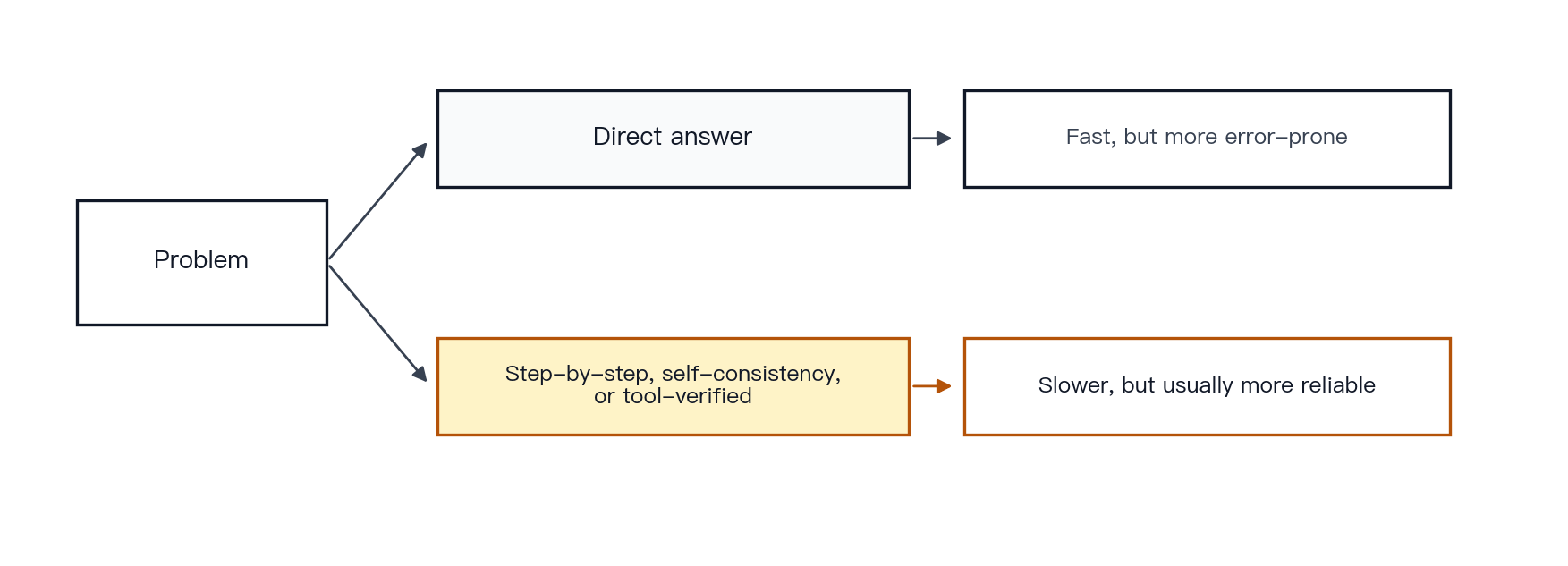
Figure 14 · Direct answer versus step-by-step reasoning. The slower path with verification is usually more reliable for tasks that require multiple steps.
Example. Problem: “Roger has 5 balls. He buys 2 more cans, with 3 balls per can. How many balls does he have in total?” A one-shot direct answer is more likely to fail. The same model is more reliable when it first computes 2 × 3 = 6 and then 5 + 6 = 11. Reliability improves further if the multiplication is executed by a calculator.
Common misconception. If the model writes out steps, the logic is sound and the answer is correct. Written steps often help, but they do not guarantee correctness. Text that looks like reasoning is not the same as reliable mathematical or logical validity.
Key point. LLMs can exhibit reasoning-like behavior. A precise framing is that they have learned a broad repertoire of problem-solving patterns, not that they contain an infallible logic engine.
Chapter 16 · Why prompts matter
Concept. A prompt is a task brief. A clear role, goal, background, set of constraints, output format, and quality criteria make the output easier to control and verify.
Mechanism. OpenAI’s documentation describes prompting as the way users instruct the model, with output quality often depending on prompt quality [35]. Anthropic’s prompt-engineering documentation adds an important caveat: not every failure should be addressed by prompt edits. Some failures require a different model, a system redesign, retrieval, tools, or better evaluation [38]. System-message design also matters, because system prompts define role, tone, format, and safety boundaries.

Figure 15 · Practical prompt template. Role, goal, background, constraints, output format, and quality criteria.
Anatomy of a good prompt. A strong prompt contains six blocks: role, goal, background, constraints, output format, and quality criteria. For example: “You are a financial analyst. Based on the attached PDF, summarize the risks. Output a four-column table: Risk · Evidence · Impact · Uncertainty. If you cannot find evidence for a risk, write ‘no supporting evidence in the document.’” The value of this prompt is not that it makes the model smarter. It narrows the task, makes the output checkable, and reduces unsupported generalization.
Common misconception. A long or clever enough prompt can solve any problem. Prompts operate within the limits of the model, the available context, the connected tools, and the surrounding system design. They are important, but they are not a universal solution.
Key point. A good prompt is a precise, executable, and verifiable task brief.
Chapter 17 · One complete LLM product request
Concept. In production, “user asks, model answers” is only the visible layer. A real product request passes through authentication, safety policy, retrieval, tools, output validation, logging, and evaluation.
Mechanism. Consider the request: “Analyze this earnings report and summarize the investment risks.” A production system typically performs the following steps:
Accept the request.
Run authentication and safety checks.
Read the uploaded file.
Chunk the document.
Retrieve and rerank relevant passages.
Assemble the prompt.
Call the model.
Invoke calculation tools when needed.
Generate structured output.
Attach citations.
Return the result.
Log the request and output for evaluation.
OpenAI’s structured-output and function-calling documentation explains how to constrain output schemas and connect tools [36]. HELM highlights that production quality is broader than accuracy; robustness, calibration, fairness, toxicity, and efficiency also matter [34].
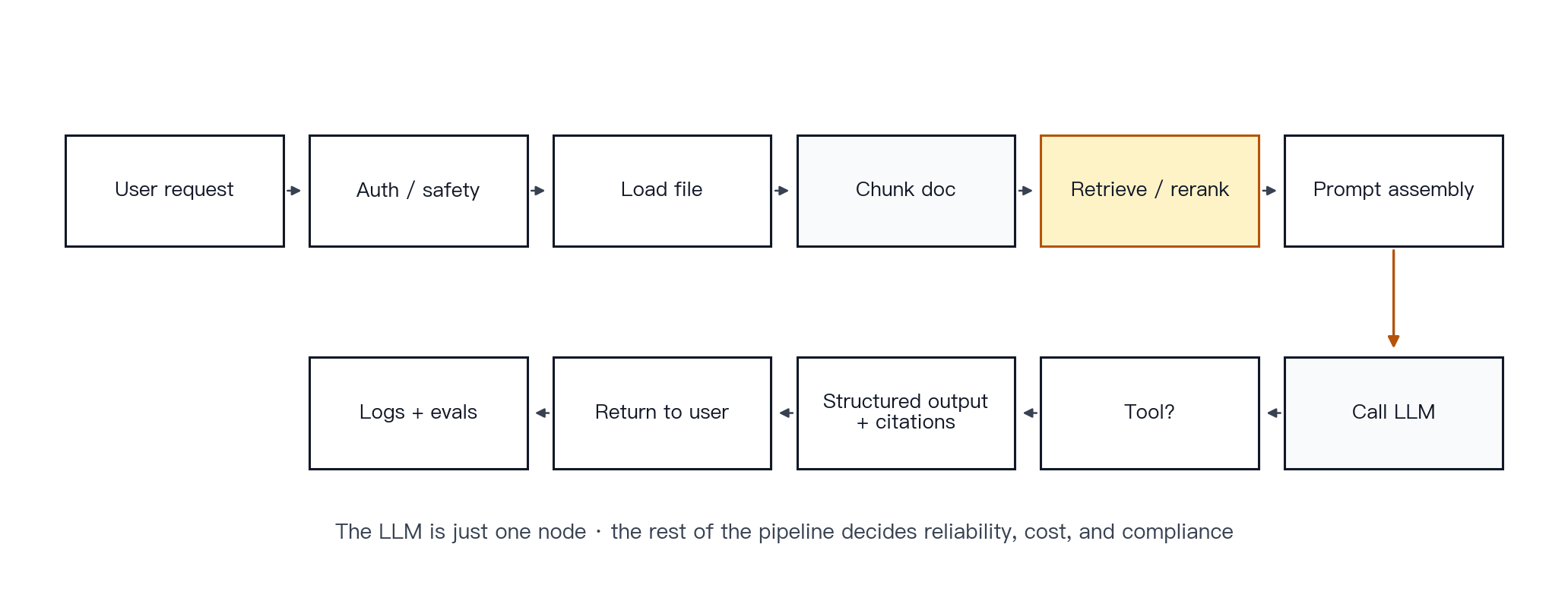
Figure 16 · Real LLM product request pipeline. An end-to-end earnings-analysis pipeline. The LLM is one node in a larger system; the surrounding pipeline makes the output more reliable.
Example. If the earnings report includes metrics such as year-over-year growth or cash-flow coverage ratios, a well-designed system asks the model to extract the numbers and sends the arithmetic to a calculator. That is usually more reliable than asking the model to do the calculation internally.
Common misconception. A strong base model is enough to build a strong product. Production quality depends on the joint design of model, data, tools, prompts, safety, evaluation, and cost controls.
Key point. A fluent answer in a production product is rarely just the model speaking. It is the result of a larger engineering pipeline.
Part IV · Misconceptions and learning roadmap
Chapter 18 · Common misconceptions
1. An LLM is just a search engine.
Why it’s wrong: Search engines retrieve from existing documents. LLMs generate text from context. These are different operations.
Correct view: Many great products combine an LLM with search or RAG, but the two are not the same thing.
2. An LLM knows everything.
Why it’s wrong: The parameters compress a lot of knowledge, but knowledge goes stale, is missing, or was never well-represented in training.
Correct view: Treat it as “a widely-read assistant who cannot always verify what it remembers,” not as a comprehensive database.
3. More parameters always mean a better model.
Why it’s wrong: Training tokens, data quality, and training strategy matter just as much.
Correct view: Bigger models have higher ceilings, but Chinchilla and the LLaMA family show that “smaller but trained well” can outperform “larger but trained poorly.” [3][5]
4. If it sounds fluent, it is correct.
Why it’s wrong: Linguistic fluency and factual correctness are not the same property.
Correct view: Hallucinations tend to occur precisely when the model sounds most confident.
5. RAG eliminates hallucinations.
Why it’s wrong: Retrieval can fail. Ranking can be wrong. Chunking can be wrong. The model can still misuse the context it received.
Correct view: RAG is a serious mitigation, not a guarantee.
6. Prompting can solve any problem.
Why it’s wrong: Some failures are about model capability, missing tools, or system design, not prompt wording.
Correct view: Prompts are important. They are not a replacement for retrieval, tools, evaluation, or safety design.
7. Agents can autonomously handle complex tasks.
Why it’s wrong: Multi-step planning propagates and amplifies any single error across the entire chain.
Correct view: Agents are a powerful, high-risk design pattern. They still require constraints, monitoring, and evaluation.
8. The model has a real human consciousness.
Why it’s wrong: The cited papers and official documentation discuss language modeling, alignment, and behavior design. They do not establish consciousness.
Correct view: From an engineering perspective, the safest framing is “a powerful statistical generator,” not “a digital mind.”
9. The model only copies its training data.
Why it’s wrong: If it only copied, it could not do few-shot generalization or composition [2]; and yet research shows models can also memorize and leak fragments of training data [17].
Correct view: Both generalization and memorization are real. Acknowledge both, not just one.
10. Open-source is automatically worse (or closed-source is automatically better).
Why it’s wrong: Capability depends on the model, the training process, the data, the surrounding system design, and the use case. No open-versus-closed label determines quality in every setting.
Correct view: Compare on task performance, cost, controllability, safety, latency, and deployment requirements, not on the “open vs closed” label.
Chapter 19 · One overview diagram
This chapter adds no new concepts. It places training and inference on one canvas so the full pipeline is visible.
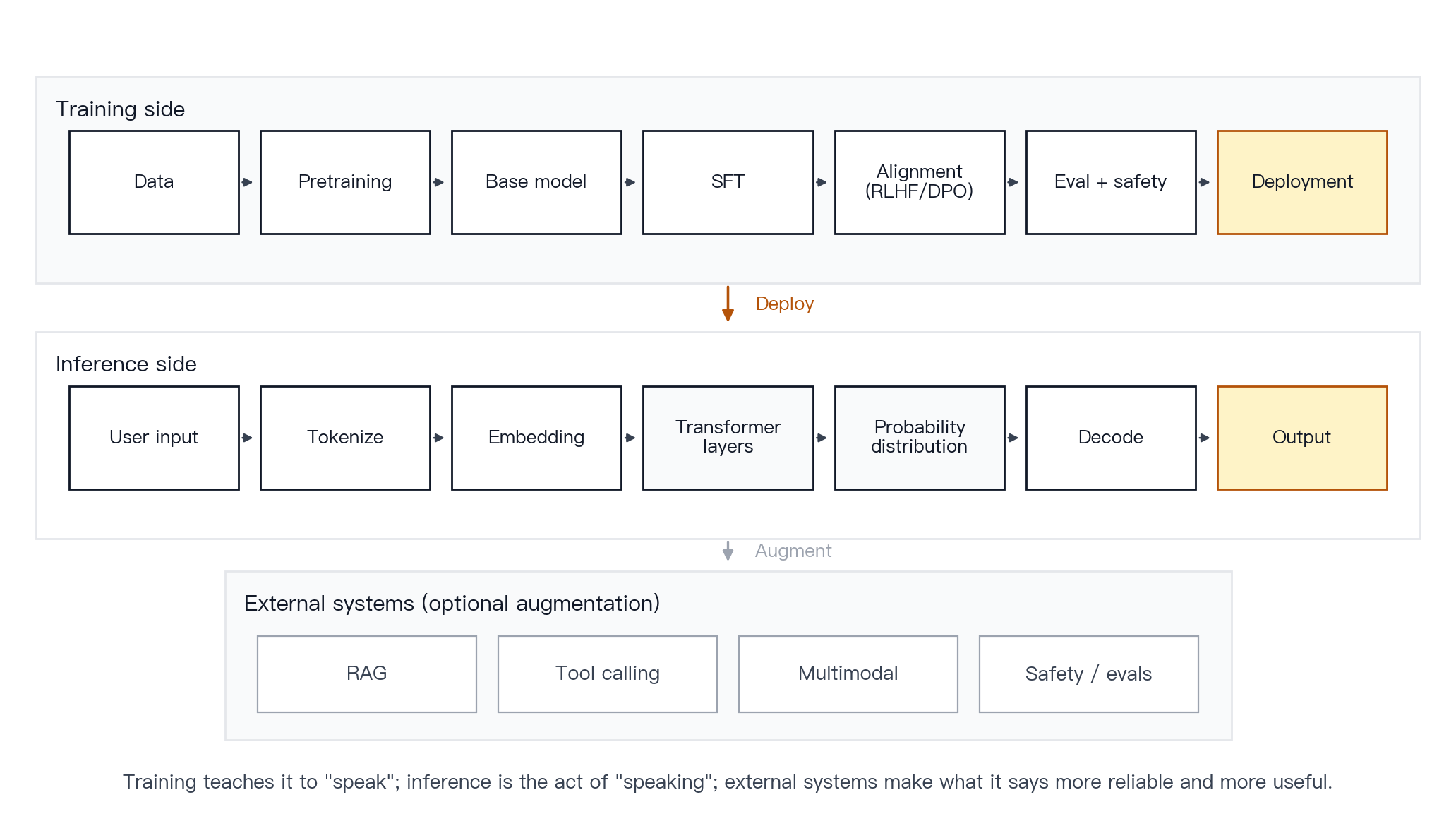
Figure 17 · End-to-end LLM overview. The training side runs from data through pretraining, SFT, alignment, and evaluation to deployment; the inference side runs from user input through tokenization, embedding, Transformer layers, and decoding to output, with retrieval and tools added as needed.
One-sentence takeaway. An LLM predicts the next token from context. Product capability comes from the model plus the external systems built around it.
Chapter 20 · Learning roadmap
For non-technical users. Focus on tokens, context, hallucinations, prompting, RAG, and tool calls. The goal is not to train a model. It is to use models correctly, spot the failure modes, and ask better questions.
For PMs, operators, and founders. Focus on application architecture, RAG, agents, cost, latency, risk, and evaluation. The goal is to design a real LLM pipeline that can ship to production, not to stop at a demo.
For early-career engineers. Focus on API usage, prompt engineering, vector databases, RAG, structured outputs, tool calling, and evaluation. The goal is to build LLM applications that actually behave reliably.
For AI engineers. Go deep on Transformers, training, alignment, inference optimization, KV cache, throughput and latency, model compression, and benchmarking. The goal is to optimize the model and the system, not just call an existing API.
Glossary
Definitions below follow the usage of the papers and official documentation cited throughout this primer.
Representation
Token — The smallest unit of text the model actually processes.
Tokenization — The process of splitting raw text into tokens.
Embedding — The dense numeric vector that each token is mapped into.
Vector space — The high-dimensional space those vectors live in.
Layer — One block in the network that progressively refines the representation.
Parameter — A learnable numeric weight inside the model.
Architecture and runtime
Transformer — The modern sequence-modeling architecture built around attention.
Self-attention — The mechanism by which each position weights every other position in the context.
Multi-head attention — Multiple attention heads operating in parallel, each capturing different relations.
Inference — The model running in production to generate outputs from inputs.
Decoding — The procedure for picking each output token from the next-token distribution.
Temperature / top-k / top-p — Sampling parameters that control randomness and the candidate set.
Context window — The maximum number of tokens that can fit in one request.
System prompt — The system-level message that sets role, rules, and constraints.
Training and alignment
Pretraining — Language-modeling training over a huge corpus to establish broad capability.
Fine-tuning — Continued training on more specific data.
SFT (Supervised Fine-Tuning) — Fine-tuning on curated instruction-response demonstrations.
RLHF (Reinforcement Learning from Human Feedback) — Aligning the model using reinforcement learning on human preferences.
DPO (Direct Preference Optimization) — A simpler, more direct alternative to traditional RLHF for preference optimization.
Alignment — Shaping model behavior to match human goals and safety norms.
Safety — Design and training that reduce harmful or risky outputs.
Evaluation — Multi-dimensional measurement of model and system quality.
Systems and products
Hallucination — Output that sounds plausible but is factually wrong.
RAG (Retrieval-Augmented Generation) — Retrieve external knowledge first, then generate with it in context.
Vector database — A system that stores embeddings and runs efficient similarity search.
Tool calling — Letting the model emit structured calls that the application then executes.
Agent — A multi-step execution pattern: model + goal + tools + memory + planning.
Multimodal model — A model that can jointly process text, images, audio, or video.
Latency — The wall-clock delay from request to response.
Cost — The total cost of inference, storage, bandwidth, and operations.
Deployment — Shipping the model and its surrounding system into production.
References
Papers and official documentation cited throughout this primer. Links point to primary sources (arXiv preprints, official API documentation, or research blog posts).
Architecture and pretraining
[1] Vaswani, A., et al. (2017). Attention Is All You Need. NeurIPS 2017. https://arxiv.org/abs/1706.03762
[2] Brown, T., et al. (2020). Language Models are Few-Shot Learners (GPT-3). NeurIPS 2020. https://arxiv.org/abs/2005.14165
[3] Touvron, H., et al. (2023). LLaMA: Open and Efficient Foundation Language Models. https://arxiv.org/abs/2302.13971
[4] Kaplan, J., et al. (2020). Scaling Laws for Neural Language Models. https://arxiv.org/abs/2001.08361
[5] Hoffmann, J., et al. (2022). Training Compute-Optimal Large Language Models (Chinchilla). https://arxiv.org/abs/2203.15556
Representations, tokens, and interpretability
[6] Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient Estimation of Word Representations in Vector Space (word2vec). https://arxiv.org/abs/1301.3781
[7] Sennrich, R., Haddow, B., & Birch, A. (2016). Neural Machine Translation of Rare Words with Subword Units (BPE). https://arxiv.org/abs/1508.07909
[8] Devlin, J., et al. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. https://arxiv.org/abs/1810.04805
[9] Tenney, I., Das, D., & Pavlick, E. (2019). BERT Rediscovers the Classical NLP Pipeline. https://arxiv.org/abs/1905.05950
[10] Clark, K., Khandelwal, U., Levy, O., & Manning, C. D. (2019). What Does BERT Look At? An Analysis of BERT’s Attention. https://arxiv.org/abs/1906.04341
Decoding and sampling
[11] Holtzman, A., Buys, J., Du, L., Forbes, M., & Choi, Y. (2020). The Curious Case of Neural Text Degeneration (nucleus sampling). ICLR 2020. https://arxiv.org/abs/1904.09751
Alignment, SFT, and safety
[12] Ouyang, L., et al. (2022). Training Language Models to Follow Instructions with Human Feedback (InstructGPT). https://arxiv.org/abs/2203.02155
[13] Rafailov, R., et al. (2023). Direct Preference Optimization: Your Language Model is Secretly a Reward Model (DPO). https://arxiv.org/abs/2305.18290
[14] Bai, Y., et al. (2022). Constitutional AI: Harmlessness from AI Feedback. https://arxiv.org/abs/2212.08073
Hallucination and uncertainty
[15] Ji, Z., et al. (2023). Survey of Hallucination in Natural Language Generation. https://arxiv.org/abs/2202.03629
[16] Kalai, A., Nachum, O., et al. (2025). Why Language Models Hallucinate (OpenAI research). https://openai.com/research/why-language-models-hallucinate
[17] Carlini, N., et al. (2021). Extracting Training Data from Large Language Models. https://arxiv.org/abs/2012.07805
Retrieval-augmented generation (RAG)
[18] Lewis, P., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. https://arxiv.org/abs/2005.11401
[19] Karpukhin, V., et al. (2020). Dense Passage Retrieval for Open-Domain Question Answering (DPR). https://arxiv.org/abs/2004.04906
[20] Johnson, J., Douze, M., & Jégou, H. (2017). Billion-scale similarity search with GPUs (Faiss). https://arxiv.org/abs/1702.08734
[21] Yan, S., et al. (2024). Corrective Retrieval Augmented Generation (CRAG). https://arxiv.org/abs/2401.15884
[22] Liu, N. F., et al. (2023). Lost in the Middle: How Language Models Use Long Contexts. https://arxiv.org/abs/2307.03172
Tool use and agents
[23] Schick, T., et al. (2023). Toolformer: Language Models Can Teach Themselves to Use Tools. https://arxiv.org/abs/2302.04761
[24] Yao, S., et al. (2022). ReAct: Synergizing Reasoning and Acting in Language Models. https://arxiv.org/abs/2210.03629
Reasoning and chain-of-thought
[25] Wei, J., et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. https://arxiv.org/abs/2201.11903
[26] Wang, X., et al. (2022). Self-Consistency Improves Chain-of-Thought Reasoning in Language Models. https://arxiv.org/abs/2203.11171
[27] Chen, W., et al. (2022). Program of Thoughts Prompting: Disentangling Computation from Reasoning. https://arxiv.org/abs/2211.12588
[28] Yao, S., et al. (2023). Tree of Thoughts: Deliberate Problem Solving with Large Language Models. https://arxiv.org/abs/2305.10601
Multimodality
[29] Dosovitskiy, A., et al. (2021). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (ViT). ICLR 2021. https://arxiv.org/abs/2010.11929
[30] Radford, A., et al. (2021). Learning Transferable Visual Models From Natural Language Supervision (CLIP). https://arxiv.org/abs/2103.00020
[31] Alayrac, J.-B., et al. (2022). Flamingo: a Visual Language Model for Few-Shot Learning. https://arxiv.org/abs/2204.14198
[32] Liu, H., et al. (2023). Visual Instruction Tuning (LLaVA). https://arxiv.org/abs/2304.08485
Serving systems and long context
[33] Kwon, W., et al. (2023). Efficient Memory Management for Large Language Model Serving with PagedAttention (vLLM). https://arxiv.org/abs/2309.06180
Evaluation
[34] Liang, P., et al. (2022). Holistic Evaluation of Language Models (HELM). https://arxiv.org/abs/2211.09110
Official developer documentation
[35] OpenAI. Tokenization and Tokens · API guide. https://platform.openai.com/docs/guides/text-generation
[36] OpenAI. Function Calling and Structured Outputs. https://platform.openai.com/docs/guides/function-calling · https://platform.openai.com/docs/guides/structured-outputs
[37] OpenAI. Prompt Caching. https://platform.openai.com/docs/guides/prompt-caching
[38] Anthropic. Context windows and prompt engineering. https://docs.claude.com/en/docs/build-with-claude/context-windows · https://docs.claude.com/en/docs/build-with-claude/prompt-engineering/overview
[39] Anthropic. Tool use with Claude. https://docs.claude.com/en/docs/agents-and-tools/tool-use/overview
[40] Anthropic. Prompt caching. https://docs.claude.com/en/docs/build-with-claude/prompt-caching
Disclaimer
This primer is the author’s personal study notes and teaching write-up. Nothing here constitutes investment, legal, medical, or other professional advice. The cited papers, official documentation, and third-party materials are used for educational illustration; the author makes no representation, express or implied, as to their accuracy or completeness.
Views expressed are solely the author’s and do not represent any employer or third-party organization. Product, model, and company names mentioned belong to their respective owners.